
June 2026 | Kunya
There is a concept in AI that most people have never heard of. Yet it is quietly the single most important factor in whether an AI gives you a useful answer or a useless one. It is called a context window — and once you understand it, you will never think about AI the same way.
Let's start with something you already know.
Your Brain Is Running the Most Impressive Context Engine Ever Built
Right now, without thinking about it, you are carrying an enormous amount of context.
You know why you opened this article. You know what you were searching for before you found it. You know what happened at work this morning, what your relationship with your boss is like, what your goals are for this year. You remember a conversation you had three weeks ago that subtly changed how you think about a problem. You carry the emotional context of your day. You know what "that thing we talked about" refers to without anyone explaining it.
That is all context. And you hold it effortlessly. Your brain stitches together decades of memories, preferences, emotions, and background knowledge in real time — and uses all of it to understand even the simplest sentence.
When your partner texts you "can you pick up the usual?", you know exactly what that means. There is no data attached to that message. The context lives in your head.
AI does not work like that. Not yet, anyway.
Your brain runs a context engine that no AI has matched — stitching together decades of memory, emotion, and knowledge in real time.
So What Is a Context Window?
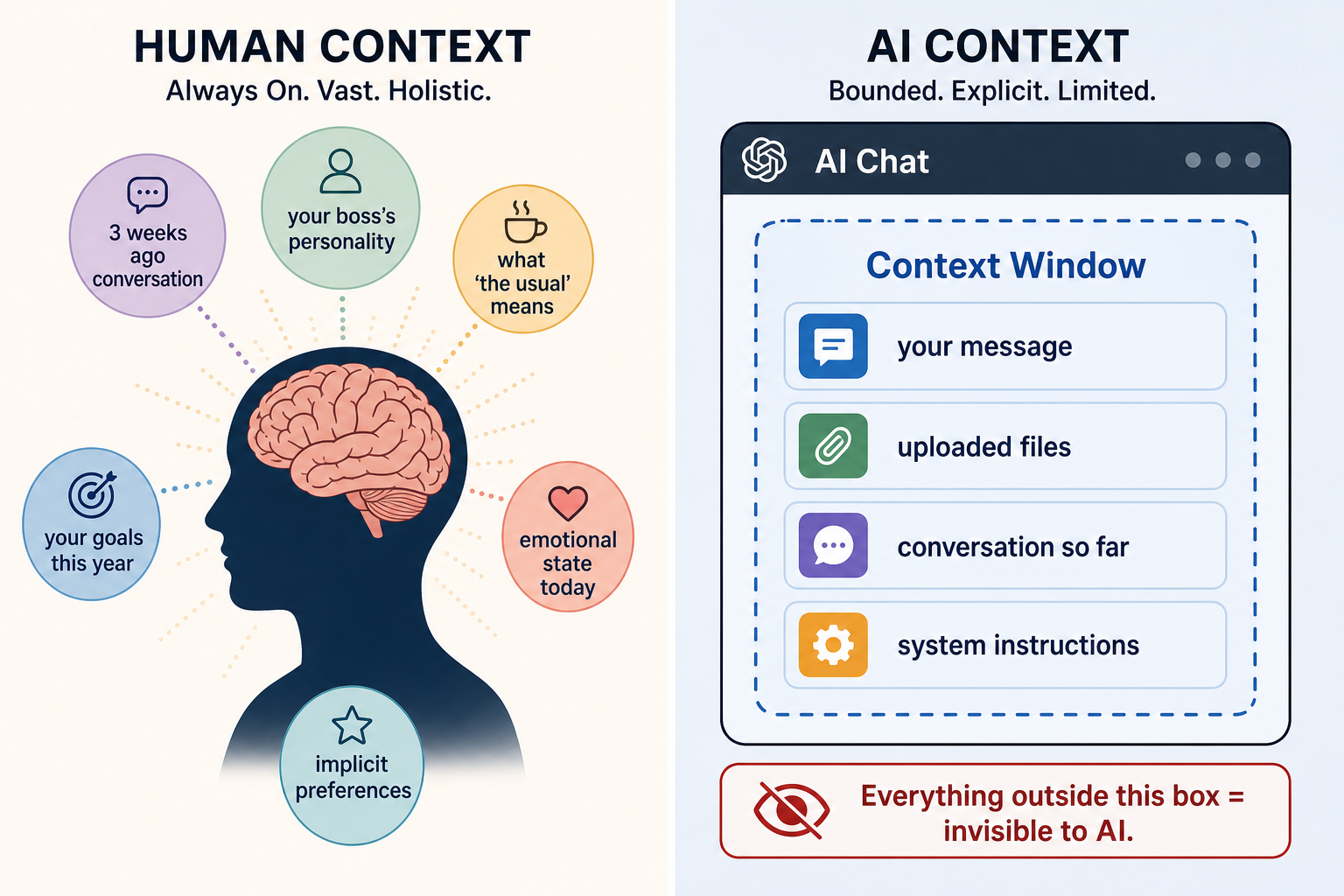
A context window is the amount of information an AI can hold and pay attention to at one time.
Every time you open a chat with an AI model, it starts fresh. It does not remember the conversation you had with it yesterday. It does not know your name unless you tell it. It does not carry any background knowledge about you, your business, or your goals. The only thing it "knows" is what is currently inside its context window: your message, any files you uploaded, the instructions given to it, and the conversation history so far.
When that window fills up, things start to fall out. The model either summarizes what came before, drops earlier parts of the conversation, or simply loses track of things you told it.
Think of it like working with a brilliant colleague who has no long-term memory. Every meeting, you have to re-introduce yourself, explain the project from scratch, and repeat the context they need. They are smart. They just cannot remember.
Tokens: The Unit of Context
Context windows are measured in tokens, not words or characters.
A token is roughly 3 to 4 characters of text. The word "context" is about two tokens. A full page of text is roughly 500 to 700 tokens. An average novel is around 100,000 tokens.
Here is a rough real-world guide:
Tokens | What That Looks Like |
|---|---|
4,000 | A few pages of text |
32,000 | A short novella |
128,000 | A full-length non-fiction book |
200,000 | About 500 pages of documents |
1,000,000 | An entire codebase, a legal case file, 40,000 lines of code |
This matters because when you send an AI a message, the entire conversation history counts toward the limit. Your message, the AI's previous replies, any documents you pasted in — all of it is using up context. Once you hit the limit, something has to give.

The context window is the AI's working memory — everything it can see right now. When it fills up, earlier content starts to fall out.
Why Context Is Everything
Here is the honest take: context is the whole game.
An AI model's raw intelligence matters less than you think if it does not have the right information to work with. You could hand the most capable AI model in the world a question with no context and get a generic, mediocre answer. Or you could give a slightly simpler model full context — your goals, your audience, the tone you want, the background on the situation — and get something genuinely useful.
Think about the difference between asking a stranger for advice vs. asking a close friend. The stranger might be smarter. But the friend knows you. They know your history, your constraints, your taste. Their advice lands differently because it is grounded in context.
That is exactly what happens with AI. The quality of the output is almost always a function of the quality and completeness of the context you provide — not just how powerful the model is.
This is also why people get frustrated with AI. They ask a vague question, get a vague answer, and assume the tool is not that useful. What they are actually experiencing is a context problem.
The Context Window Race in 2026
The AI industry knows how important context is. That is why the last two years have been defined by a quiet arms race to expand context windows as far as possible.
Here is where things stand as of mid-2026:
Model | Context Window |
|---|---|
Llama 4 Scout | 10,000,000 tokens |
Gemini 3.1 Pro | 2,000,000 tokens |
GPT-5.5 | 1,000,000 tokens |
Claude Opus 4.8 | 1,000,000 tokens |
DeepSeek V4 Pro | 1,000,000 tokens |
Grok 4.3 | 1,000,000 tokens |
Claude Sonnet 4.6 | 1,000,000 tokens |
To put that in perspective: 1 million tokens is enough to hold an entire software codebase, a month of customer support conversations, or a full legal case file — all in a single session.
Just two years ago, 128,000 tokens was considered impressive. Today, 1 million tokens is the new baseline for frontier models. Gemini 3.1 Pro pushes to 2 million. Llama 4 Scout reaches 10 million.
Bigger Is Not Always Better, Though
Here is the part that most articles skip.
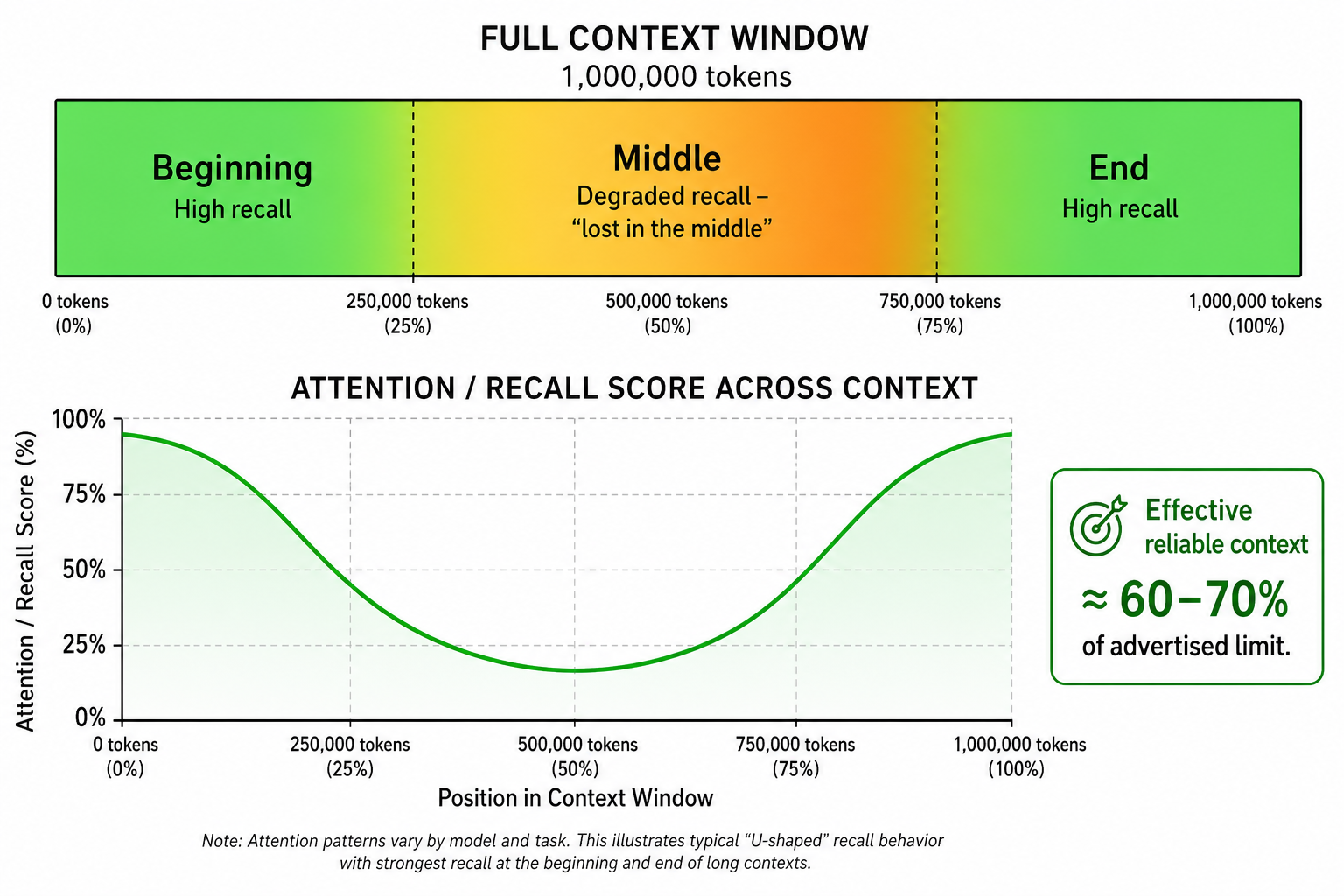
Having a large context window does not mean a model uses all of it equally well. Research in 2026 consistently shows that AI models tend to pay more attention to information at the beginning and end of the context window — and can "lose" things that get buried in the middle.
This is sometimes called context rot or the "lost in the middle" problem. Even the most advanced frontier models show degraded recall when critical information is buried deep in a 1-million-token prompt.
The "Lost in the Middle" Problem
A model advertising a 1M token window is not the same as a model that reliably understands and remembers everything across all 1M tokens. The effective usable context is often closer to 60–70% of the advertised limit for reliable performance. This is why how you structure your context matters just as much as how much you have.
The Difference Between Context Windows and Memory
People often confuse context windows with memory. They are not the same thing.
A context window is active and temporary. It is what the model can see right now, in this conversation. When the conversation ends, that context is gone.
Memory, in the AI sense, is something different: a system that stores information outside of the conversation and retrieves it later. Some AI products are starting to build persistent memory features on top of their models. But the underlying context window is still the engine — memory is just a way of feeding useful information back into it.
Your brain does both at once without you even noticing. AI is still catching up.
What This Means for How You Use AI
A few practical takeaways:
Front-load the important stuff. When starting a conversation with an AI, give it context upfront. Your goal, your audience, your constraints, your preferences. Do not make it guess. The more context you give at the start, the better every response will be.
Long conversations degrade. The longer a chat goes, the more context gets crowded out. If you are working on something complex, consider starting fresh sessions for different phases of the work rather than one endless thread.
Paste in what matters. If you have a document, a brief, or a set of instructions that are relevant — paste them in. AI cannot read your mind. Context it cannot see is context it cannot use.
Bigger context windows genuinely unlock new use cases. With 1M+ token models, you can now have an AI read your entire business document library before answering a question. Or analyze a full codebase. Or synthesize months of customer feedback at once. These are not marginal improvements — they are qualitatively different capabilities.
Why Kunya Is Built Around This
Most AI platforms give you a model. Kunya gives you the right model, with the right context, at the right moment — and that distinction is everything.
We give you access to all of the frontier models mentioned above across every context tier, in one place. Whether you need Gemini 3.1 Pro's 2-million-token window to ingest a massive document library, Claude Opus 4.8 for long-horizon agentic work, or GPT-5.5 for complex reasoning with full context preserved — you can switch between them in the same interface without juggling separate subscriptions, separate logins, or separate bills.
But access to big context windows is only half the problem.
The other half is knowing what to actually put in them.
Dumping everything you have into a 1-million-token context is not a strategy. It is noise. The "lost in the middle" problem we described earlier does not disappear just because you have more room — it gets worse when the context is bloated, unfocused, or poorly structured. A context window filled with irrelevant information is actively harmful. It dilutes signal. It sends the model chasing the wrong things.
This is why Kunya is built around intelligent context management, not just large context access.
Kunya's agents and tools are designed to find exactly what belongs in the context window before the model ever sees it. Rather than loading everything and hoping for the best, Kunya's retrieval tools pull the specific documents, snippets, conversation history, or data points that are actually relevant to your current task. Think of it like a research assistant who reads the entire archive so you do not have to — and hands you only the three pages that matter.
Intelligent context retrieval: rather than loading everything, Kunya's tools surface only what's actually relevant — so the model works with signal, not noise.
This does two things. First, it dramatically improves the quality of the AI's response, because the context it receives is dense with signal rather than diluted by noise. Second, it protects you from burning unnecessary tokens on content that was never going to help. Context windows are powerful, but they are not free. Every token counts, especially at scale.
Our agentic workflows take this further. Kunya agents can break complex tasks into steps, passing only the relevant context forward at each stage rather than carrying the full weight of everything through every step. The model always has what it needs. It never carries more than it should.
This philosophy is also foundational to how we built KunyaV1, our own proprietary large language model. KunyaV1 was not designed around raw parameter count or benchmark leaderboard performance. It was designed around context efficiency — the ability to extract maximum understanding from a well-structured, precisely scoped context window. Where many models are trained to handle whatever gets thrown at them, KunyaV1 is trained to work with clean, purposeful context and return responses that reflect that precision back to you.
It is a different bet than most of the industry is making. But we think it is the right one. Because after everything the research shows, and after everything we have built and tested, we keep arriving at the same conclusion: the model that uses its context wisely will outperform the model that simply has more of it.
Context is everything. Kunya is built on that belief.
Try Kunya Free
Explore 100+ models across every context tier — from 1M to 10M tokens — in one platform. No credit card required.


